
I recently came across this brief LessWrong discussion:
What should we expect from GPT-3?
When it will appear? (My guess is 2020).
Will it be created by OpenAI and will it be advertised? (My guess is that it will not be publicly known until 2021, but other companies may create open versions before it.)
How much data will be used for its training and what type of data? (My guess is 400 GB of text plus illustrating pictures, but not audio and video.)
What it will be able to do? (My guess: translation, picture generation based on text, text generation based on pictures – with 70 per cent of human performance.)
How many parameters will be in the model? (My guess is 100 billion to trillion.)
How much compute will be used for training? (No idea.)
At first, I’d have been skeptical. But then this was brought to my attention:
The guy behind this, /u/JonathanFly, actually commented on the /r/MediaSynthesis post:
OMG I forgot I never did do a blog writeup for this. But this person almost did it for me lol.
https://iforcedabot.com/how-to-use-the-most-advanced-language-model-neural-network-in-the-world-to-draw-pokemon/ just links to my tweets. Need more time in my life.
This whole thing started because I wanted to make movies with GPT-2, but I really wanted color and full pictures, so I figured I should start with pictures and see if it did anything at all. I wanted the movie ‘frames’ to have the subtitles in the frame, and I really wanted the same model to draw both the text and the picture so that they could at least in theory be related to each other. I’m still not sure how to go about turning it into a full movie, but it’s on the list of things to try if I get time. I think for movies, I would need a much smaller and more abstract ASCII representation, which makes it hard to get training material. It would have to be like, a few single ASCII letters moving across the screen. I could convert every frame from a movie like I did the pokemon but it would be absolutely huge — a single Pokemon can use a LOT of tokens, many use up more than the 1024 token limit even (generated over multiple samples, by feeding the output back in as the prompt.)
Finally, I’ve also heard that GPT-2 is easily capable of generating code or anything text-based, really. It’s NLP’s ImageNet moment.
This made me think.
“Could GPT-2 be used to write music?”
If it were trained on enough data, it would gain a rough understanding of how melodies work and could then be used to generate the skeleton for music. It already knows how to generate lyrics and poems, so the “songwriting” aspect is not beyond it. But if I fed enough sheet music into it, then theoretically it ought to create new music as well. It would even theoretically be able to generate that music, at least in the form of MIDI files (though generating a waveform is also possible, if far beyond it).
Surely if a person like me figured this out, someone much more substantial should have realized this, then?
Lo and behold, those substantial people at OpenAI preempted me with MuseNet.
MuseNet was not explicitly programmed with our understanding of music, but instead discovered patterns of harmony, rhythm, and style by learning to predict the next token in hundreds of thousands of MIDI files. MuseNet uses the same general-purpose unsupervised technology as GPT-2, a large-scale transformer model trained to predict the next token in a sequence, whether audio or text.
And with this, I realized that GPT-2 is essentially a very, very rudimentary proto-AGI. It’s just a language model, yes, but that brings quite a bit with it. If you understand natural language, you can meaningfully create data— and data & maths is just another language. If GPT-2 can generate binary well enough, it can theoretically generate anything that can be seen on the internet.
Scott Alexander of Slate Star Codex also realized this:
Why do I believe this? Because GPT-2 works more or less the same way the brain does, the brain learns all sorts of things without anybody telling it to, so we shouldn’t be surprised to see GPT-2 has learned all sorts of things without anybody telling it to – and we should expect a version with more brain-level resources to produce more brain-level results. Prediction is the golden key that opens any lock; whatever it can learn from the data being thrown at it, it will learn, limited by its computational resources and its sense-organs and so on but not by any inherent task-specificity.
I don’t want to claim this is anywhere near a true AGI. “This could do cool stuff with infinite training data and limitless computing resources” is true of a lot of things, most of which are useless and irrelevant; scaling that down to realistic levels is most of the problem. A true AGI will have to be much better at learning from limited datasets with limited computational resources. It will have to investigate the physical world with the same skill that GPT investigates text; text is naturally machine-readable, the physical world is naturally obscure. It will have to have a model of what it means to act in the world, to do something besides sitting around predicting all day. And it will have to just be better than GPT, on the level of raw power and computational ability. It will probably need other things besides. Maybe it will take a hundred or a thousand years to manage all this, I don’t know.
But this should be a wake-up call to people who think AGI is impossible, or totally unrelated to current work, or couldn’t happen by accident. In the context of performing their expected tasks, AIs already pick up other abilities that nobody expected them to learn. Sometimes they will pick up abilities they seemingly shouldn’t have been able to learn, like English-to-French translation without any French texts in their training corpus. Sometimes they will use those abilities unexpectedly in the course of doing other things. All that stuff you hear about “AIs can only do one thing” or “AIs only learn what you program them to learn” or “Nobody has any idea what an AGI would even look like” are now obsolete.
But GPT-2 is too weak. Even GPT-2 Large. What we’d need to put this theory to the test is the next generation: GPT-3.
This theoretical GPT-3 is GPT-2 + much more data. Far more than even GPT-2 Large uses— and for reference, no one has actually publicly used GPT-2 Large. Grover (which is based on the 1.5B parameter version) is specialized for faking news articles, not any text-generated task. GPT-2 Large is already far beyond what we are playing with, and GPT-3 (and further iterations of GPT-X) have to be much larger still.
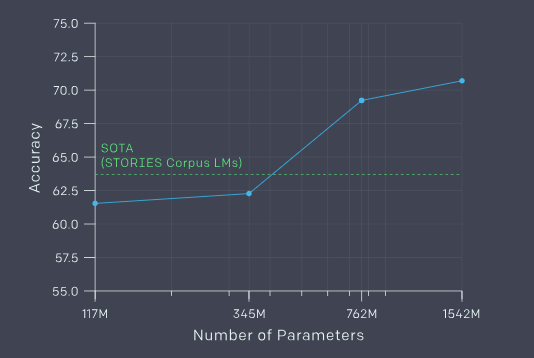
And while it’s impressive that GPT-2 is a simple language modeler fed ridiculous amounts of data, GPT-3 will only impress me if it comes close to matching the MT-DNN or XLNet in terms of commonsense reasoning. Of course, the MT-DNN and XLNet are roughly par-human at the Winograd Schema challenge, 20% ahead of GPT-2 in real numbers. Passing the challenge at such a level means it has human-like reading comprehension, and if coupled with text generation, we’d get a system that’s capable of continuing any story or answering any question about a text passage in-depth as well as achieving near-perfect coherence with what it creates. If GPT-3 is anywhere near that strong, then there’s no doubt that it will be considered a proto-AGI even by the most diehard skeptics.
Now when I say that it’s a proto-AGI, I don’t mean to say that it’s part of a spectrum that will lead to AGI with enough data. I only use “proto-AGI” because my created term, “artificial expert intelligence”, never took off and thus most people have no idea what that is.
But “artificial expert intelligence” or AXI is exactly what GPT-2 is and a theoretical GPT-3 would be.
Artificial Expert Intelligence: Artificial expert intelligence (AXI), sometimes referred to as “less-narrow AI”, refers to software that is capable of accomplishing multiple tasks in a relatively narrow field. This type of AI is new, having become possible only in the past five years due to parallel computing and deep neural networks.
At the time I wrote that, the only AI I could think of that qualified was DeepMind’s AlphaZero which I was never fully comfortable with, but the more I learn about GPT-2, the more it feels like the “real deal.”
An AXI would be a network that works much like GPT-2/GPT-3, using a root capability (like NLP) to do a variety of tasks. GPT-3 may be able to generate images and MIDI files, something it wasn’t explicitly made to do and sounds like an expansion beyond merely predicting the next word in a sequence (even though that’s still fundamentally what it does). More importantly, there ought to still be limitations. You couldn’t use GPT-2 for tasks completely unrelated to natural language processing, like predicting protein folding or driving cars for example, and it will never gain its own agency. In that regard, it’s not AGI and never will be— AGI is something even further beyond it. But it’s virtually alien-like compared to ANI, which can only do one thing and must be reprogrammed to do anything else. It’s a kind of AI that lies in between the two, a type that doesn’t really have a name because we never thought much about its existence. We assumed that once AI could do more than one specific thing, we’d have AGI.
It’s like the difference between a line (ANI), a square (AXI), and a tesseract (AGI). Or, if AGI is 1,000 and ANI is a 1, AXI would be something closer to a 10 up to even 100.
GPT-2 would be considered a fairly weak AXI under this designation since nothing it does comes close to human-level competence at tasks (not even the full version). GPT-3 might become par-human at a few certain things, like holding short conversations or generating passages of text. It will be so convincing that it will start freaking people out and make some wonder if OpenAI has actually done it. A /r/SubSimulatorGPT3 would be virtually indistinguishable from an actual subreddit, with very few oddities and glitches. It will be the first time that a neural network is doing magic, rather than the programmers behind it being so amazingly competent. And it may even be the first time that some seriously consider AGI as a possibility for the near future.
Who knows! Maybe if GPT-2 had the entire internet as its parameters, it would be AGI as well as the internet becoming intelligent. But at the moment, I’ll stick to what we know it can do and its likely abilities in the near future. And there’s nothing suggesting GPT-2 is that generalized.
I suppose one reason why it’s also hard to gauge just how capable GPT-2 Large is comes down to the fact so few people have access to it. One guy remade it, but he decided not to release it. As far as I can tell, it’s just because he talked with OpenAI and some others and decided to respect their decision instead of something more romantic (i.e. “he saw just how powerful GPT-2 really was”). And even if he did release it, it was apparently “significantly worse” than OpenAI’s original network (his 1.5 billion parameter version was apparently weaker than OpenAI’s 117 million parameter version). So for right now, only OpenAI and whomever they shared the original network with know the full scope of GPT-2’s abilities, however far or limited they really are. We can only guess based on GPT-2 Small and GPT-2 Medium, and as aforementioned, they are quite limited compared to the full thing.
Nevertheless, I can at least confidently state that GPT-2 is the most general AI on the planet at the moment (as far as we know). There are very good reasons for people to be afraid of it, though they’re all because of humans rather than the AI itself. And I, for one, am extremely excited to see where this goes while also being amazed that we’ve come this far.
What exactly should GPT-3 be able to do? That, I cannot answer because I’m not fully aware of the full breadth of GPT-2, but the knowledge that it and MuseNet are fundamentally the same network trained on different data sets suggests to me that a theoretical 100B parameter version ought to be able to do at least the following:
- Reach roughly 90% accuracy on either the Winograd Schema Challenge or the WNLI
- Generate upwards of 1,000 to 2,000 words of coherent, logical text based on a short prompt
- Increase the accuracy of its output by adding linked resources from which it can immediately draw/spin/summarize
- Generate extended musical pieces
- Generate low-resolution images, perhaps even short gifs
- Translate between languages, perhaps even figuring out context better than Google Translate
- Understand basic arithmetic
- Generate usable code
- Caption images based on the data presented
- Generate waveforms rather than just MIDIs
- Gain a rudimentary understanding of narrative (i.e. A > B > C)
All this and perhaps even more from a single network. Though it’s probable we’ll get more specialized versions (like MuseNet), the basic thing will be a real treat.
I myself don’t understand the specifics, so I can’t say that GPT-X will be able to use language modeling to learn how to play an Atari video game, but I can predict that it may be able to create an Atari-tier video game some time next decade. Any data-based tasks can be automated by an agent such as GPT-X, and this includes things like entertainment and news. It’s the purest form of “synthetic media”.


{kind=link}
{kind=link}
{kind=link}